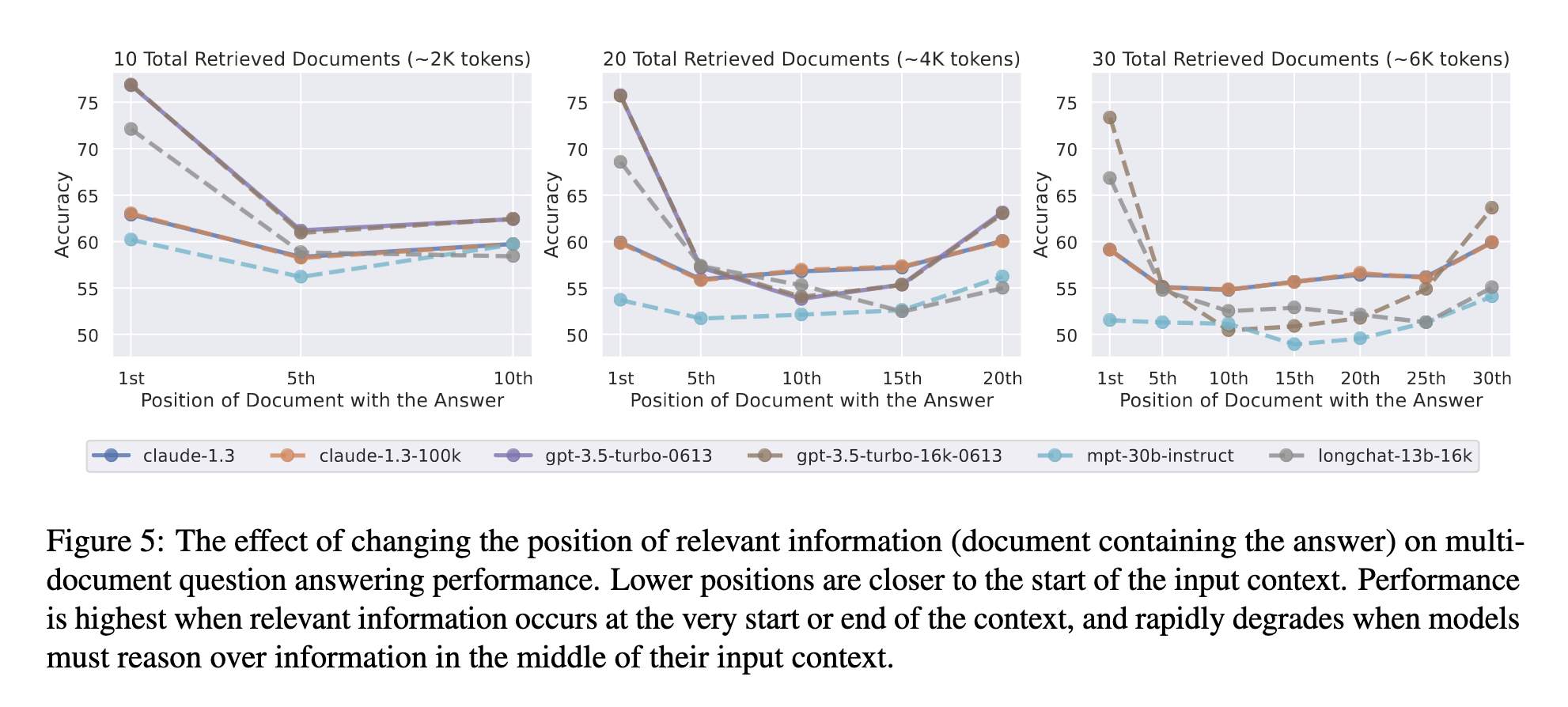
Almost 1 year ago, Lost in the Middle: How Language Models Use Long Contexts paper was published that empirically investigated the effectiveness of finding information in the input context depending on the location of the correct answer in the context among other relevant information. The researchers used gpt-3.5-turbo, gpt-3.5-turbo-16k, Claude 1.3, Claude 1.3 (100k), MPT-30B-Instruct and LongChat-13B (16k) and found that the quality jumps A LOT when you change the position of a piece of text with the correct answer among other relevant text that does not contain the answer to the question.
To measure how much the answer performance varies, the authors took 20 pieces of Wikipedia pages, only one of which contained the exact answer to the question (the rest were quite relevant but did not contain the answer to the question) and started moving the paragraph with the answer to the beginning, then further, and so on, trying all positions. As it turned out, the proportion of correct answers when placing the paragraph with the answer in the middle of the input context fell below 55%, which is the level of generating a correct answer to a question using model’s parameter memory (without passing information in a prompt). If you place the answer paragraph at the very beginning, the share of correct answers to the same question will be 75%, where the paragraph with the correct answer at the very end will be around 65%.
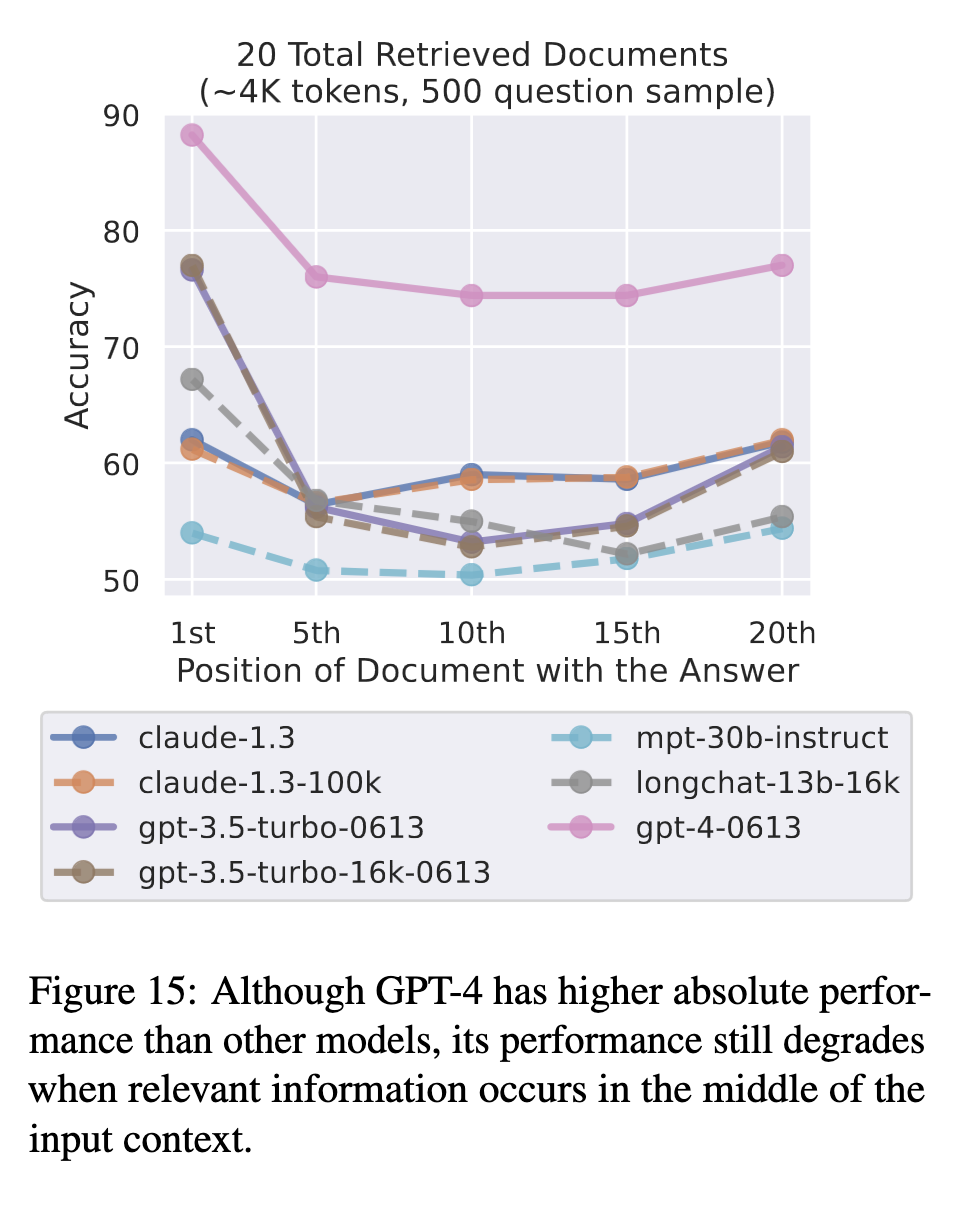
Performing a smaller experiment (because “Evaluating GPT-4 on the full multi-document QA and key-value retrieval experiments would cost upwards of $6000”) using the gpt-4-0613 model with 20 documents in the input context, it performed significantly better than any other model, although you can still see a U-shaped curve, indicating that even for newer models, the location of the answer information affects the result.
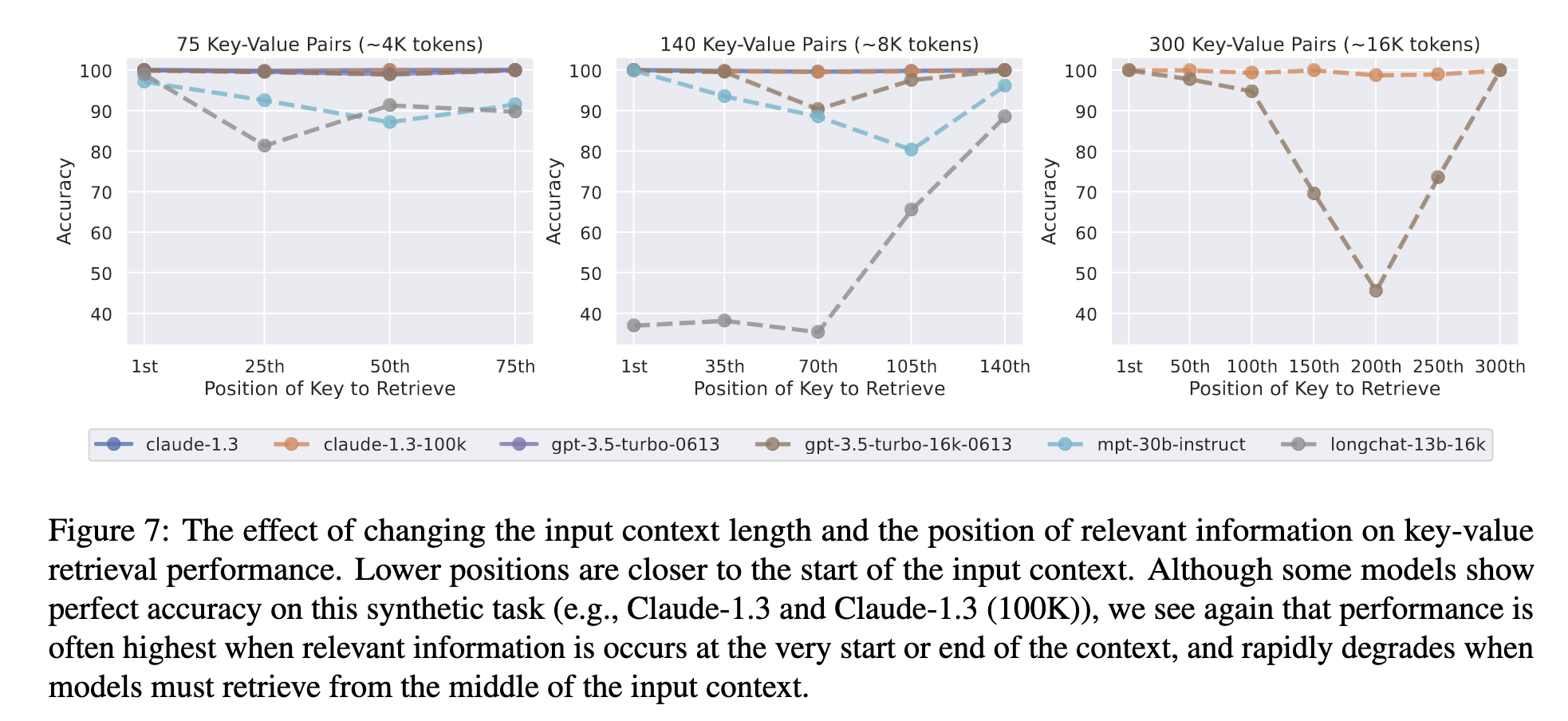
Additionally, the authors thought: “maybe the model is just confusing the information we are feeding it”? and so they decided to try to measure performance on a synthetic task. To do this, they generated 75, 140, and 300 key-value pairs where keys and values are unique, randomly-generated UUIDs, and asked the model to return the value by key. Although some models showed perfect results on this task, you can still see that the answer at the beginning or at the end gives better results.
Although almost a year has passed since the paper was written and the models have improved significantly, it is useful to know about this behavior of LLM models with a large context window.
If you find this paper summary interesting - go ahead and read the paper in full: Lost in the Middle: How Language Models Use Long Contexts